出处:
HBase 进行数据建模的方式和你熟悉的关系型数据库有些不同。关系型数据库围绕表、列和数据类型——数据的形态使用严格的规则。遵守这些严格规则的数据称为结构化数据。HBase 设计上没有严格形态的数据。数据记录可能包含不一致的列、不确定大小等。这种数据称为半结构化数据(semistructured data)。
在逻辑模型里针对结构化或半结构化数据的导向影响了数据系统物理模型的设计。关系型数据库假定表中的记录都是结构化的和高度有规律的。因此,在物理实现时,利用这一点相应优化硬盘上的存放格式和内存里的结构。同样,HBase 也会利用所存储数据是半结构化的特点。随着系统发展,物理模型上的不同也会影响逻辑模型。因为这种双向紧密的联系,优化数据系统必须深入理解逻辑模型和物理模型。
除了面向半结构化数据的特点外,HBase 还有另外一个重要考虑因素——可扩展性。在半结构化逻辑模型里数据构成是松耦合的,这一点有利于物理分散存放。HBase 的物理模型设计上适合于物理分散存放,这一点也影响了逻辑模型。此外,这种物理模型设计迫使HBase 放弃了一些关系型数据库具有的特性。特别是,HBase 不能实施关系约束(constraint)并且不支持多行事务(multirow transaction)。这种关系影响了下面几个主题。
逻辑模型:有序映射的映射集合
HBase 中使用的逻辑数据模型有许多有效的描述。图2-6 把这个模型解释为键值数据库。我们考虑的一种描述是有序映射的映射(sorted map of maps)。你大概熟悉编程语言里的映射集合或者字典结构。可以把HBase 看做这种结构的无限的、实体化的、嵌套的版本。
我们先来思考映射的映射这个概念。HBase 使用坐标系统来识别单元里的数据:[行键,列族,列限定符,时间版本]。例如,从users 表里取出Mark 的记录
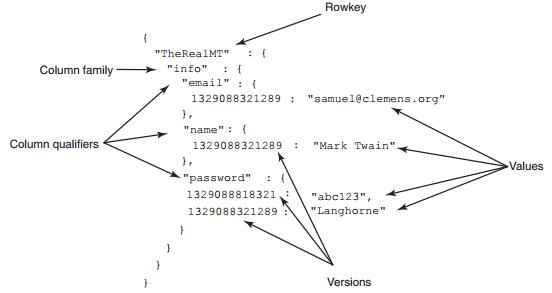
理解映射的映射的概念时,把这些坐标从里往外看。你可以想象,开始以时间版本为键、数据为值建立单元映射,往上一层以列限定符为键、单元映射为值建立列族映射,最后以行键为键列族映射为值建立表映射。这个庞然大物用Java 描述是这样的:Map<RowKey, Map<ColumnFamily, Map<ColumnQualifier, Map<Version,Data>>>>。不算漂亮,但是简单易懂。
注意我们说映射的映射是有序的。上述例子只显示了一条记录,即使如此也可以看到顺序。注意password 单元有两个时间版本。最新时间版本排在稍晚时间版本之前。HBase 按照时间戳降序排列各时间版本,所以最新数据总是在最前面。这种物理设计明显导致可以快速访问最新时间版本。其他的映射键按照升序排列。现在的例子看不到这一点,让我们插入几行记录看看是什么样子:
wu@ubuntu:~/opt/twitbase$ java -cp target/twitbase-1.0.0.jar HBaseIA.TwitBase.UsersTool add HMS_Surprise "Patrick O'Brian" aubrey@sea.com abc123
Successfully added user <User: HMS_Surprise, Patrick O'Brian, aubrey@sea.com, 0>
wu@ubuntu:~/opt/twitbase$ java -cp target/twitbase-1.0.0.jar HBaseIA.TwitBase.UsersTool add GrandpaD "Fyodor Dostoyevsky" fyodor@brothers.net abc123
Successfully added user <User: GrandpaD, Fyodor Dostoyevsky, fyodor@brothers.net, 0>
wu@ubuntu:~/opt/twitbase$ java -cp target/twitbase-1.0.0.jar HBaseIA.TwitBase.UsersTool add SirDoyle "Sir Arthur Conan Doyle" art@TheQueensMen.co.uk abc123
Successfully added user <User: SirDoyle, Sir Arthur Conan Doyle, art@TheQueensMen.co.uk, 0>
现在再次列出Users 表的内容,可以看到:
wu@ubuntu:~/opt/twitbase$ java -cp target/twitbase-1.0.0.jar HBaseIA.TwitBase.UsersTool list
16/03/18 01:31:51 INFO TwitBase.UsersTool: Found 4 users.
<User: GrandpaD, Fyodor Dostoyevsky, fyodor@brothers.net, 0><User: HMS_Surprise, Patrick O'Brian, aubrey@sea.com, 0><User: SirDoyle, Sir Arthur Conan Doyle, art@TheQueensMen.co.uk, 0><User: TheRealMT, Mark Twain, samul@clemens.org, 0>实践中,设计HBase 表模式时这种排序设计是一个关键考虑因素。这是另外一个物理数据模型影响逻辑模型的地方。掌握这些细节可以帮助你在设计模式时利用这个特性。
物理模型:面向列族
就像关系型数据库一样,HBase 中的表由行和列组成。HBase 中列按照列族分组。这种分组表现在映射的映射逻辑模型中是其中一个层次。列族也表现在物理模型中。每个列族在硬盘上有自己的HFile 集合。这种物理上的隔离允许在列族底层HFile 层面上分别进行管理。进一步考虑到合并,每个列族的HFile 都是独立管理的。
HBase 的记录按照键值对存储在HFile 里。HFile 自身是二进制文件,不是直接可读的。存储在硬盘上HFile 里的Mark 用户数据如图2-8 所示。注意,在HFile 里Mark 这一行使用了多条记录。每个列限定符和时间版本有自己的记录。另外,文件里没有空记录(null)。如果没有数据,HBase 不会存储任何东西。因此列族的存储是面向列的,就像其他列式数据库一样。一行中一个列族的数据不一定存放在同一个HFile 里。Mark 的info数据可能分散在多个HFile 里。唯一的要求是,一行中列族的数据需要物理存放在一起。
"TheRealMT" , "info" , "email" , 1329088321289 , "samuel@clemens.org"
"TheRealMT" , "info" , "name" 1329088321289 , "Mark Twain""TheRealMT" , "info", "password" , 1329088818321 , "abc123","TheRealMT" , "info" , "password", 1329088321289 , "Langhorne"如果users 表有了另一个列族,并且Mark 在那些列里有数据。Mark 的行也会在那些HFile 里有数据。每个列族使用自己的HFile 意味着,当执行读操作时HBase 不需要读出一行中所有的数据,只需要读取用到列族的数据。面向列意味着当检索指定单元时,HBase 不需要读占位符(placeholder)记录。这两个物理细节有利于稀疏数据集合的高效存储和快速读取。
让我们增加另外一个列族到users 表,以存储TwitBase 网站上的活动,这会生成多个HFile。让HBase 管理整行的一整套工具如图所示。HBase 称这种机制为region,我们在后面会讨论。
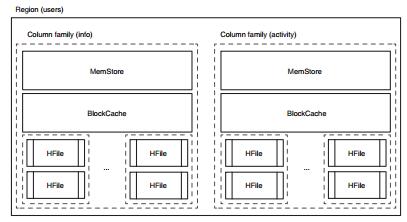
在图中可以看到,访问不同列族的数据涉及完全不同的MemStore 和HFile。列族activity 数据的增长并不影响列族info 的性能。